
首个Gemini桌面端曝光,系统级Agent空降PC!
首个Gemini桌面端曝光,系统级Agent空降PC!首个Gemini桌面端曝光,全新Gemini 3.2/3.5闪现,不到1分钟盲写2000行代码,操作系统级Agent真的来了。
来自主题: AI资讯
7643 点击 2026-05-20 10:13
 搜索
搜索
首个Gemini桌面端曝光,全新Gemini 3.2/3.5闪现,不到1分钟盲写2000行代码,操作系统级Agent真的来了。
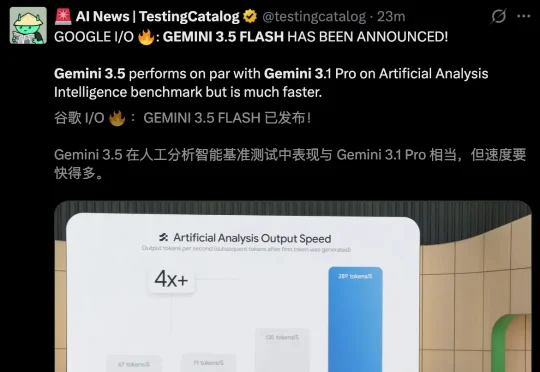
劈柴和Hassabis把半年大招一晚清仓了!Gemini Omni任意输入生成视频,3.5 Flash断层碾压一切,Spark 7×24h云端替你干活。这次,谷歌是要把OpenAI和Anthropic一起给埋了。
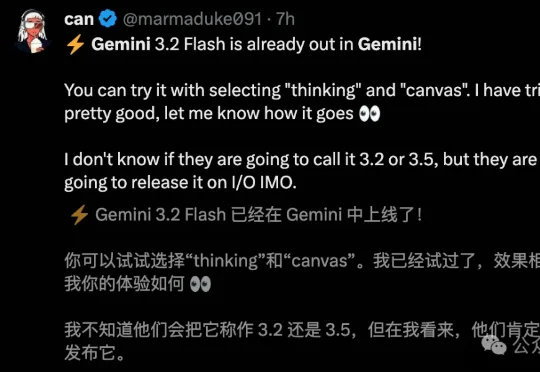
发布会还没开,谷歌彻底藏不住了!Gemini 3.2 Flash网页端静默上线,被开发者抓了个正着。单次提示狂飙2200行代码、手搓Windows 98,直接把自家旗舰Pro按在地上摩擦。
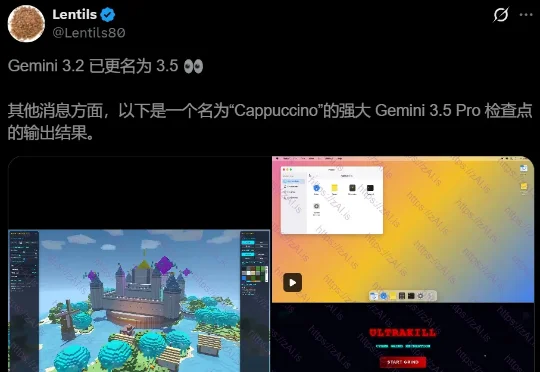
就在刚刚,Gemini 3.5提前曝光了! 网友Lentils放出最新消息,代号「Cappuccino」的Gemini 3.5 Pro检查点已经开始产出。而就在几个小时前,传闻还是Gemini 3.2,没想到一下子就替换成了Gemini 3.5。

他人生最大的一次跨步是博士毕业,毅然决然离开深造9年的物理,来到崭新的AI行业。过去两年,他先后在Anthropic和Google DeepMind出任研究科学家,参与了Claude 3.7、4.5、Gemini 3等关键模型的开发过程。

OpenAI刚用Deep Research抢了先手,谷歌直接掀桌!DeepMind祭出研究智能体双杀,Max版质量评分从66.1%暴拉到93.3%,知识工作自动化的军备竞赛正式进入贴身肉搏。

谷歌真是急了。 前脚刚传来消息,称谷歌联合创始人谢尔盖·布林重启“创始人模式”,亲自督战并组建精英“突击队”,全力提升Gemini在AI编程和自主智能体等关键能力上追赶Anthropic等对手。 后脚

本报告基于XSCT Arena平台,对 Qwen3.6-Plus-Preview(阿里云,2026-04-02 发布)在文字能力(xsct-l)、网页生成(xsct-w)、Agentic 任务(xsct-a)三大场景下的表现进行系统评测,并与Claude Sonnet 4.6、GPT-5.4、Gemini 3.1 Pro、Kimi K2.5、
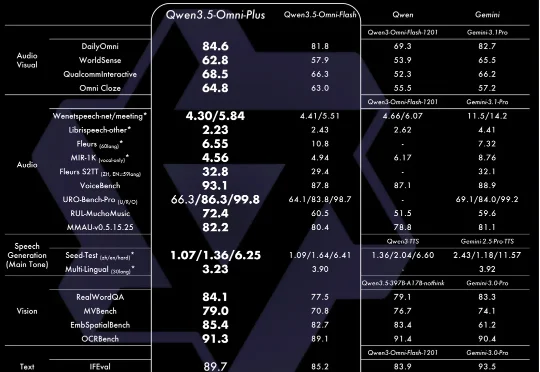
阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。
昨日凌晨,谷歌正式推出其最高质量的音频和语音模型——实时语音模型Gemini 3.1 Flash Live,并在Gemini App、Search Live以及Google AI Studio中同步开放,其中后者以预览版本向开发者提供。